
Rate limiting mechanisms are a crucial feature of public APIs. They protect these services from becoming overloaded with too many requests while providing fair access to all clients.
Every public API service has limits on how many API calls clients can make over a given duration. But, how are these rate limiting mechanisms implemented?
To answer that, we’ll explore how to implement a basic rate limiter from scratch for an API service built with FastAPI by using Redis. We’ll build the same type of system that powers API request management in many enterprise platforms.
Contents#
- Basic Design of a Rate Limiter
- Token Bucket Algorithm for Rate Limiting
- Rate Limiter Implementation
- Testing Our Rate Limiter
- Conclusion
Basic Design of a Rate Limiter#
Incoming client requests are first routed to a middleware, which acts as a gatekeeper to the API backend service. Here, the middleware checks whether a client’s request needs to be rate limited before allowing or rejecting them.
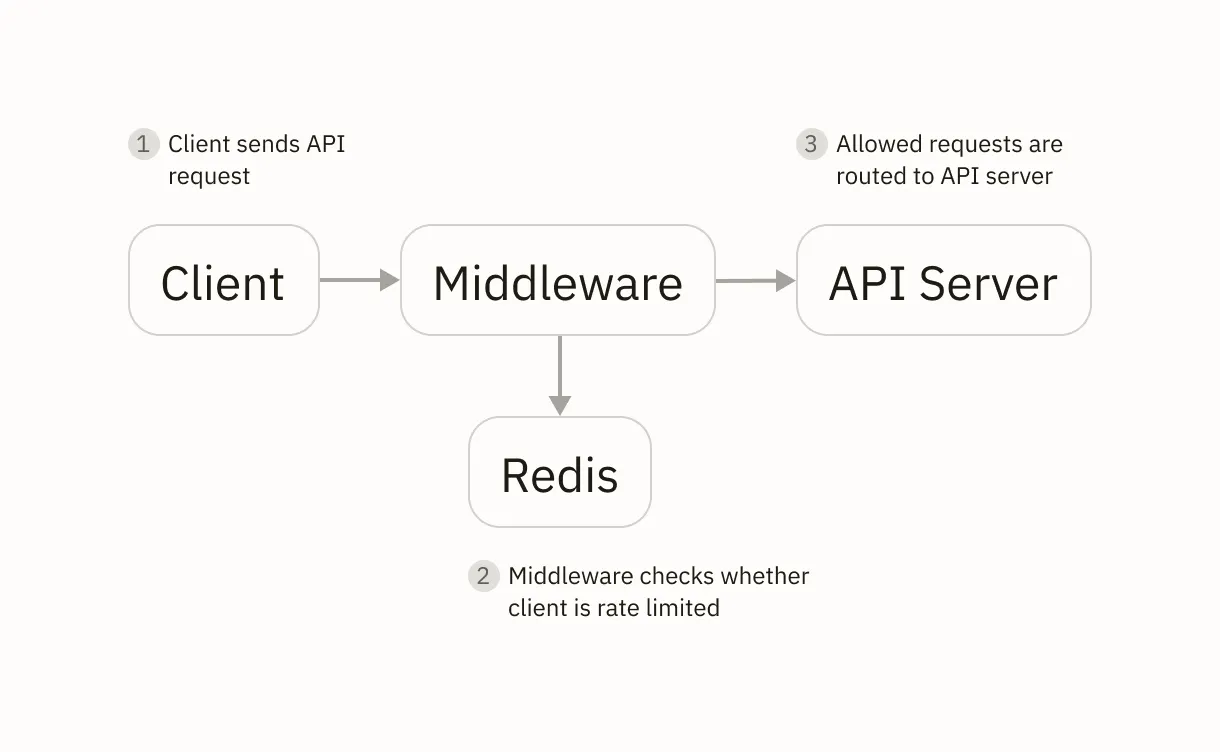
To do this, it leverages a cache provided by a Redis service. Here, Redis is a high-performance key-value store we’ll use to track to track API usage for each client.
Putting this all together requires implementing an algorithm to determine when to rate limit a client. While there are various algorithms available, we’ll focus on one of the simplest: the token bucket algorithm.
Token Bucket Algorithm for Rate Limiting#
The token bucket algorithm is a straightforward approach to rate limiting. Imagine each client is assigned a bucket that contains a set number of tokens.
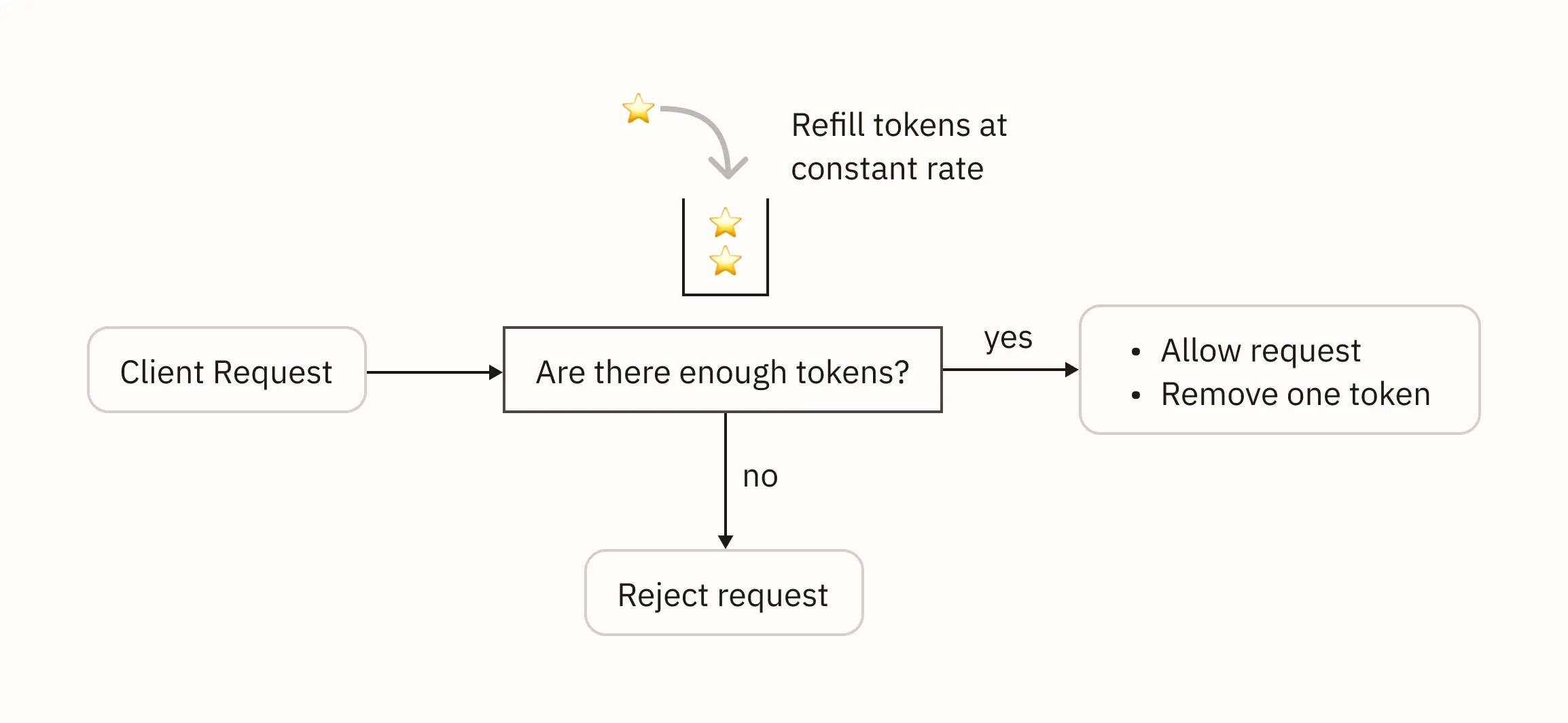
Each time a client makes an API call, we remove one token from their bucket. In addition, the client’s bucket is refilled with tokens at predetermined rate.
If a client has no more tokens in their bucket, they can’t make new API requests until more tokens are added.
While this algorithm is intuitive, it requires careful consideration to choose the bucket capacity and token replenishment rate that are appropriate for your use case.
Rate Limiter Implementation#
In this section, we’ll write code to implement a rate limiter with the token bucket algorithm.
Note that if you’re trying to do this for a production system, there are libraries such as slowapi and fastapi-limiter that are sufficient for this task.
Github Repo#
You can find the code for this section in this Github repository.
Redis Lua Script#
First, we’ll start by defining the logic that our Redis service needs to track client requests. Redis allows us to define this logic by writing a Lua script. If you’re curious of the benefits of Lua scripting in this case, check out this resource for more details.
The Lua script described in this section is an edited version of the one presented in this Github gist. In this project, the contents of this script will be stored in a file called request_rate_limiter.lua. First, we’ll define variables that we’ll use in the rest of the script:
local tokens_key = KEYS[1] -- key used to identify client's bucket
local timestamp_key = KEYS[2] -- key to obtain unix time of client's previous API request
local refill_rate = tonumber(ARGV[1]) -- token bucket refill rate
local capacity = tonumber(ARGV[2]) -- token bucket capacity
local time_now = tonumber(ARGV[3]) -- current unix time
local requested = tonumber(ARGV[4]) -- number of tokens requested
-- time to completely fill an empty bucket
local fill_time = capacity/refill_rate
-- time to live for cached values
local ttl = math.floor(fill_time*2)Here, the middleware will provide the keys, given asKEYS, and arguments, given asARGV, for Redis to execute this script. We’ll see more details on that in the next section.
The next step focuses on fetching the cached values of the clients token count, given as last_tokens, and the Unix time of the client’s previous API request time_last_refreshed. If either of these values are nonexistent in the cache, we assign default values to them.
-- obtain current tokens in client's bucket
local last_tokens = tonumber(redis.call("get", tokens_key))
-- if the cached value is empty, then assign the client a full token bucket
if last_tokens == nil then
last_tokens = capacity
end
-- if the cached value is empty, then assign the current unix time
local time_last_refreshed = tonumber(redis.call("get", timestamp_key))
if time_last_refreshed == nil then
time_last_refreshed = time_now
endAfter that, we now compute the number of tokens the client has gained in the time since their last request:
local delta_time_since_refresh = math.max(0, time_now - time_last_refreshed)
local replenished_tokens = delta_time_since_refresh * refill_rate
-- make sure the number of tokens doesn't exceed bucket's capacity
local filled_tokens = math.min(capacity, last_tokens + replenished_tokens)From here, we can now decide whether to allow the client’s request:
local allowed = filled_tokens >= requested
local new_tokens = filled_tokens
if allowed then
new_tokens = filled_tokens - requested
end
redis.call("setex", tokens_key, ttl, new_tokens)
redis.call("setex", timestamp_key, ttl, time_now)
return { allowed, new_tokens }The redis.call function is used here to cache quantity of tokens left in the client’s bucket and the current timestamp. We assign a time to life for these cached values in case the client doesn’t make any further requests for an extended period.
The output values are returned as a tuple to the middleware, which we’ll define next.
FastAPI Middleware#
FastAPI allows you to define the middleware by using the middleware(“http”) decorator like so:
from fastapi import FastAPI, Request
app = FastAPI()
@app.middleware("http")
async def check_request(request: Request, call_next):
client_ip = request.client.host
response = call_next(request)
return responseThis middleware defined above extracts the client’s IP address, which we can we can use to distinguish between clients. After that, it uses the call_next function to route the request to the endpoint specified by the client’s API call.
We can edit this middleware to implement rate limiting with a few more additions. First, we need to specify the max number of tokens a client has access to and the rate at which tokens are replenished. We also need to label how many tokens left that client has access to and the timestamp during which the client’s token bucket as last replenished.
These additions are shown below:
from fastapi import FastAPI, Request
from time import time
BUCKET_REPLENISH_RATE = 2
BUCKET_CAPACITY = 10
TOKENS_PER_REQUEST = 1
app = FastAPI()
@app.middleware("http")
async def check_request(request: Request, call_next):
client_ip = request.client.host
prefix = "request_rate_limiter." + client_ip
keys = [prefix + ".tokens", prefix + ".timestamp"]
args = [BUCKET_REPLENISH_RATE, BUCKET_CAPACITY, time(), TOKENS_PER_REQUEST]
response = call_next(request)
return responseHere, we’ve define two keys to track a client’s tokens and the timestamp of the client’s last request. We’ve also created a list of arguments that will be provided to the Redis Lua script.
Speaking of which, we now need to load the script and allow the middleware to communicate with the Redis service.
Redis has a function to load a script into its cache and provide a hash that can be used to invoke this script.
The snippet below creates an asynchronous Redis client, loads the Lua script, and provides the corresponding hash to the variable script_hash.
from contextlib import asynccontextmanager
from redis.asyncio import Redis
import os
redis_client = None
script_hash = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global redis_client, script_hash
redis_client = Redis(host=os.getenv("REDIS_HOST"), port=os.getenv("REDIS_PORT"))
script_hash = await get_script_hash(redis_client, "./request_rate_limiter.lua")
yield
await redis_client.close()
app = FastAPI(lifespan=lifespan)This uses the lifespan events API from FastAPI to execute this logic when the FastAPI server starts up. The app will close the client connection to the Redis service upon shutdown.
From here, we can implement rate limiting as shown below:
from fastAPI import Response
@app.middleware("http")
async def check_request(request: Request, call_next):
client_ip = request.client.host
prefix = "request_rate_limiter." + client_ip
keys = [prefix + ".tokens", prefix + ".timestamp"]
args = [BUCKET_REPLENISH_RATE, BUCKET_CAPACITY, time(), TOKENS_PER_REQUEST]
allowed, new_tokens = redis_client.evalsha(script_hash, len(keys), *keys, *args)
if allowed:
response = call_next(request)
return response
else:
return Response(
content="Too many requests",
status_code=status.HTTP_429_TOO_MANY_REQUESTS,
)However, it’s best practice provide the headers X-Rate-Limit-Remaining and X-RateLimit-Reset in the response. Here’s a revised version of the middleware that accomplishes this:
@app.middleware("http")
async def check_request(request: Request, call_next):
client_ip = request.client.host
prefix = "request_rate_limiter." + client_ip
# Redis keys for token bucket
keys = [prefix + ".tokens", prefix + ".timestamp"]
args = [BUCKET_REPLENISH_RATE, BUCKET_CAPACITY, time(), TOKENS_PER_REQUEST]
allowed, new_tokens = redis_client.evalsha(script_hash, len(keys), *keys, *args)
retry_after = math.ceil(TOKENS_PER_REQUEST / BUCKET_REPLENISH_RATE)
if allowed:
response = await call_next(request)
response.headers["X-RateLimit-Remaining"] = str(new_tokens)
response.headers["Retry-After"] = str(retry_after)
return response
else:
return Response(
content="Too many requests",
status_code=status.HTTP_429_TOO_MANY_REQUESTS,
media_type="text/plain",
headers={"X-RateLimit-Remaining": "0", "Retry-After": str(retry_after)},
)Now, let’s add an example endpoint:
@app.get("/api/example")
def get_example():
return {"message": "This is a rate limited endpoint"}In the next section, we’ll test our rate limiter on client requests to this endpoint.
Testing Our Rate Limiter#
Here’s a curl script we can use to test how the rate limiter handles several consecutive client requests:
#!/bin/bash
API_URL="http://localhost:8000/api/example"
REQUESTS=20
DELAY=0.01
echo "Testing rate limits on $API_URL ($REQUESTS requests, ${DELAY}s delay)"
echo "----------------------------------------"
for i in $(seq 1 $REQUESTS); do
response=$(curl -i -s -w "\n%{http_code}" $API_URL)
status_code=$(echo "$response" | tail -n1)
printf "\nRequest %d: Status %s%d\033[0m" $i \
$([[ $status_code == 200 ]] && echo "\033[32m" || echo "\033[31m") $status_code
echo "$response" | grep -E "X-RateLimit-Remaining|Retry-After"
[[ $i -lt $REQUESTS ]] && sleep $DELAY
done
echo -e "\n----------------------------------------\nTest completed!"This script executes 20 requests that are spaced apart by 10 ms. The script outputs the following:
Testing rate limits on http://localhost:8000/api/example (20 requests, 0.01s delay)
----------------------------------------
Request 1: Status 200
Request 2: Status 200
Request 3: Status 200
Request 4: Status 200
Request 5: Status 200
Request 6: Status 200
Request 7: Status 200
Request 8: Status 200
Request 9: Status 200
Request 10: Status 200
Request 11: Status 429
Request 12: Status 429
Request 13: Status 429
Request 14: Status 429
Request 15: Status 200
Request 16: Status 429
Request 17: Status 429
Request 18: Status 429
Request 19: Status 429
Request 20: Status 429-e
----------------------------------------
Test completed!We see that the first 10 requests succeed but that subsequent requests are rate limited. The 15th request succeeds because a token has been added to the token bucket. The other requests fail because not enough time has passed between these requests for the token bucket to refill.
Conclusion#
In this guide, we built a custom rate limiter using FastAPI and Redis. While this implementation illustrates core concepts like the token bucket algorithm and middleware integration, you should consider using libraries like slowapi or fastapi-limiter in production systems.
Even so, understanding the fundamentals of rate limiters is a necessary step toward designing scalable and resilient API systems.